8 best practices for optimizing Lambda functions
- Authors

- Name
- Tomasz Łakomy
- @tlakomy
AWS Lambda is the backbone of every serverless architecture.
While browsing endless serverless patterns, architectures and solutions available online, it's hard to find one without at least a single lambda function. Since its announcement in 2014, AWS Lambda has become a de-facto synonym for "serverless".
The promise of AWS Lambda is simple:
Source: https://aws.amazon.com/lambda/AWS Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can trigger Lambda from over 200 AWS services and software as a service (SaaS) applications, and only pay for what you use.
Note the only pay for what you use part, which clearly indicates that we, the developers, have plenty of options when it comes to optimizing our Lambda functions in terms of latency, cost and sometimes both. This post aims to give you a quick overview of the most important configuration options/best practices and how to optimize your Lambda functions.
(And no, this post won't tell you to rewrite everything in Rust)
0. Measure first, optimize later
AWS has famously established that "security is job zero" when building its services. In software optimization, "measurements are job zero" (and that's why this tip is the 0th one).
When it comes to optimizing your Lambda functions, it's hugely important to measure first and optimize later. To quote "Serverless Architectures on AWS":
You can't optimize what you can't measure.
Before you start figuring out how to optimize the latency and cost of your serverless functions, you must have a consistent approach to monitoring necessary metrics and cost.
Understand the cost breakdown of your serverless application
Before spending weeks trying to squeeze that 0.1ms out of your Lambda function performance, figure out whether it's actually worth it. Saving 10 cents per month is not exactly worth it if for instance CloudWatch Logs are 95% of your AWS bill (which happens more often than you think).
While rewriting your entire production stack to Rust sure does sound fun, it may not be necessarily in the best interest of your project. If half of your bill is caused by unused EC2 instances, shut down those first before optimizing your Lambda functions.
Monitor all necessary metrics with CloudWatch metrics
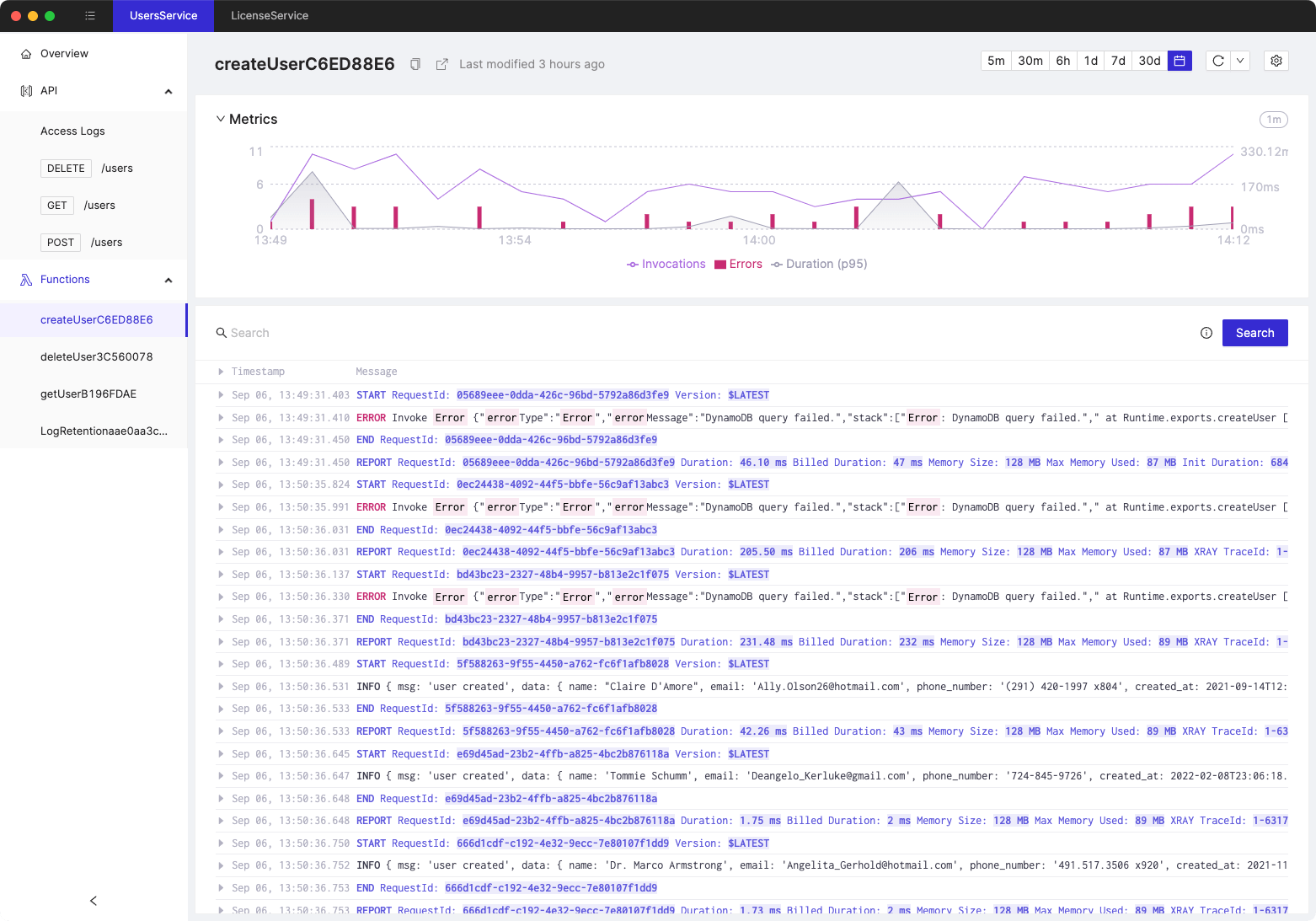
Every service used in serverless applications emits a set of standard metrics that will help you understand the performance and availability of your system. Few AWS Lambda examples:
- Invocations - total number of requests received by a given function. For instance an API Gateway custom authorizer Lambda function will be invoked way, way more often than "sign up for premium membership" one. In general you should strive to optimize the most invoked functions first, as they might be a bottleneck of your entire system (a webapp with 5 minute login flow is not exactly likely to be successful)
- Duration - total time spent in a given function. It's a good idea to optimize functions that take longer to execute, since that directly translates to larger cost and latency. Note that "longer to execute" is subjective and depends on your business requirements. In addition to that it's important to monitor for anomalies in terms of function duration (so that you can revert a Friday night commit that caused the function to run 10x slower)
- Errors - total number of errors that occurred in a given function. Note that this does not measure errors which are caused by internal issues in AWS Lambda service itself or due to throttling (since throttled function is not technically an error since it was never executed).
- Throttles - total number of Lambda function invocations that did not result in your function code being actually executed. There are a number of factors that may cause a function to be throttled, including the account-wide concurrency limit (by default 1,000 concurrenct executions, which can be raised with an AWS Support ticket) or reserved concurrency limit.
Small note on AWS Lambda limits, according to AWS docs:
- The default concurrency limit per AWS Region is 1,000 invocations at any given time.
- The default burst concurrency quota per Region is between 500 and 3,000, which varies per Region.
- There is no maximum concurrency limit for Lambda functions. However, limit increases are granted only if the increase is required for your use case.
- To avoid throttling, it's a best practice to request a limit increase at least two weeks prior to when the increase is needed.
- If you're using Lambda with CloudFront Lambda@Edge, then you must open a separate quota increase case for each Region.
Discover performance issues with AWS X-Ray.
As the name suggest, AWS X-Ray is excellent for performing an x-ray scan of what exactly is happening whenever your Lambda function gets executed. AWS X-Ray generated traces for a subset of requests that each of your Lambda function receives and presents you with a visual interface that allows developers to investigate which factores contributed e.g. to a slower than usual response time.
X-Ray trace data is retained for 30 days from the time it is recorded at no additional cost which allows you to investigate performance hiccups that happened e.g. two weeks ago.
Since X-Ray is not a free service, it's not enabled by default for every Lambda function in your account(s). Check X-Ray pricing page for reference.
Now that we've measured what we need to understand our performance bottlenecks, let's start optimizing.
1. Set proper memory size for a Lambda function
The performance of a given Lambda function depends partially on the amount of CPU and memory allocated to it (partially, because e.g. a BogoSort will never be fast, no matter how much hardware you throw at it).
AWS does not allow you to independently scale the CPU and memory allocated to a given function, developers are instead given a single setting "Memory (MB)" setting. Apart from increasing the available RAM for a given function, this setting will also influence its cost per request (functions with more memory will be billed more per 1ms) and the CPU power proportional to increase in RAM.
As of December 1st, 2020 - AWS Lambda supports up to 10 GB of memory and 6 vCPU cores for Lambda Functions.
There's a tradeoff here - functions with larger memory size cost more per 1ms while at the same time are executed faster (which means that you get charged for less milliseconds of exeuction time). For every Lambda function there's a memory setting which allows you to get the best performance/cost optimization. While you can increment your function memory setting by 128MB and run some tests yourself there's a better solution - AWS Lambda Power Tuning.
AWS Lambda Power Tuning is a state machine powered by AWS Step Functions that helps you optimize your Lambda functions for cost and/or performance in a data-driven way. Basically, you can provide a Lambda function ARN as input and the state machine will invoke that function with multiple power configurations (from 128MB to 10GB, you decide which values). Then it will analyze all the execution logs and suggest you the best power configuration to minimize cost and/or maximize performance.
2. Minimize deployment artifact size
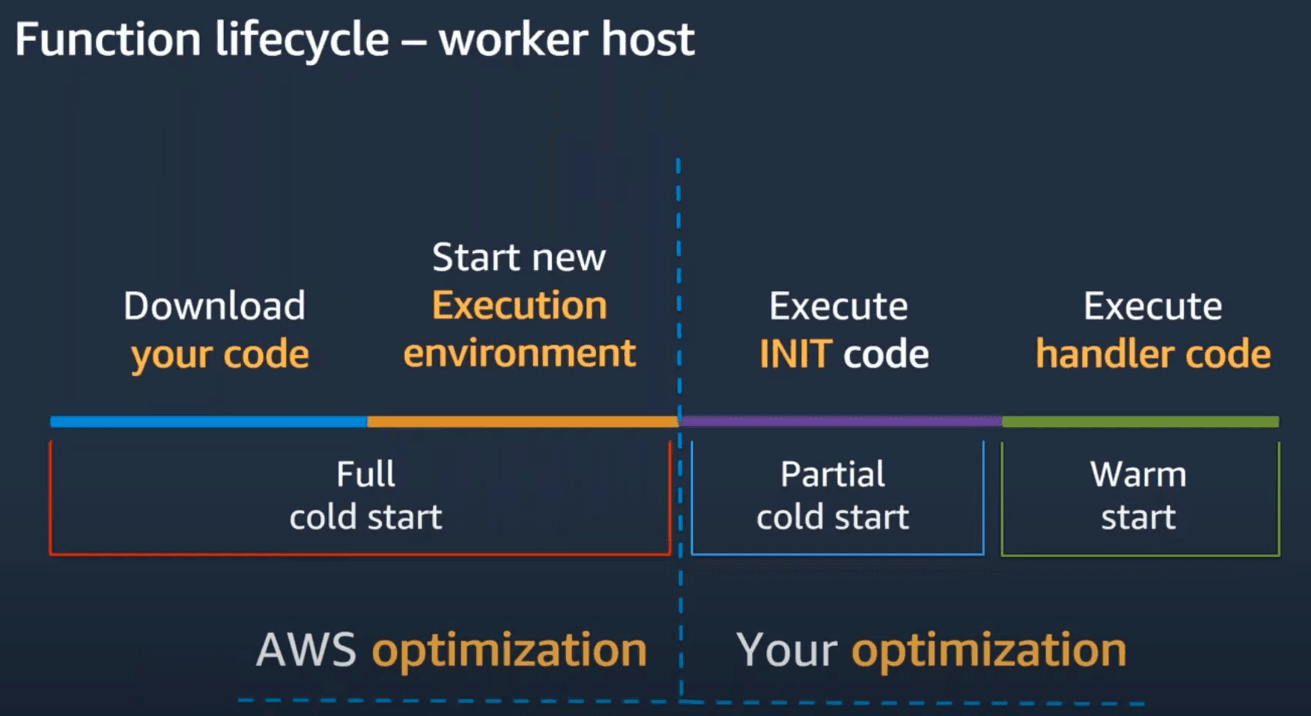
As shown above, a Lambda function livecycle has several steps, some of those are optimized by AWS itself, and some can be optimized by developers using the service.
- First, Lambda service needs to download your code
- Secondly, unless a "warm" execution environment is available, a brand new execution environment will be created
- Next, your init code (that is - everything outside of the
handlerfunction) is executed - And lastly, your
handlercode is executed
In order to optimize the time it takes to optimize downloading your code consider... shipping less of it. AWS Lambda has a limit of 250MB for the deployment artifact (so shipping your entire node_modules is out of the question) and in general - the less code you ship per a function, the faster it will be downloaded & executed during a full cold start.
Note on cold/warm starts: AWS does not publish the data on how long an environment is kept warm, but many developers agree it's for somewhere between 5 and 20 minutes. You can test it yourself by forcing a cold start (changing the Lambda function code or an environment variable will force AWS to discard the warm execution environment).
Avoiding so-called "Lambdalith" is a the best practice, building small functions which are focused on a single goal (e.g. deleteThing, createThing) is a better choice than a huge allMyBusinessLogic function, both in terms of cold start latency and maintenance.
The best practice is to carefully choose external dependencies for a Lambda function, removing everything that's not needed for the function to run. In addition to that avoid importing the whole aws-sdk in your function:
const AWS = require("aws-sdk");
const s3Client = new AWS.S3({});
await s3Client.createBucket(params);
Do this instead:
const { S3 } = require("@aws-sdk/client-s3");
const s3Client = new S3({});
await s3Client.createBucket(params);
Source: https://aws.amazon.com/blogs/developer/modular-packages-in-aws-sdk-for-javascript/
3. Optimize function logic
If you measure performance issues in a given Lambda function, perform an audit of its code. If you've avoided building a "Lambdalith", there shouldn't be too much code to read and at scale even the smallest 1% performance improvements can give noticeable improvements.
Optimize CPU-heavy algorithms used in a function, consider not fetching your entire DynamoDB table with Scan in order to fetch a single item (that's what Query is for), try to find a faster dependency that solves the same problem etc.
In addition to that, consider whether you can move initialization code outside of the handler function. Everything that's outside of the handler function is executed only during the cold start and is subsequently reused during warm invocations. As such you'd want to e.g. initialize the DynamoDB.DocumentClient once outside of the handler function and reuse it in future invocations of the function to improve its performance.
4. Consider using provisioned concurrency
Once your "Uber for X" startup gets to scale, you'll need to consider how to scale your Lambda function.
By default there's a soft limit (which can be increased with a support ticket) of 1,000 concurrent invocations of all Lambda functions in a given account (yet another reason to use multiple AWS accounts in your organization, btw). In addition to that, there's an account-wide limit on the rate at which you can scale up your concurrent executions:
Your functions' concurrency is the number of instances that serve requests at a given time. For an initial burst of traffic, your functions' cumulative concurrency in a Region can reach an initial level of between 500 and 3000, which varies per Region. Note that the burst concurrency quota is not per-function; it applies to all your functions in the Region.
After the initial burst, your functions' concurrency can scale by an additional 500 instances each minute. This continues until there are enough instances to serve all requests, or until a concurrency limit is reached. When requests come in faster than your function can scale, or when your function is at maximum concurrency, additional requests fail with a throttling error (429 status code).
Source: https://docs.aws.amazon.com/lambda/latest/dg/invocation-scaling.html#scaling-behavior
Luckily, since late 2019, AWS Lambda has a provisioned concurrency feature:
Provisioned concurrency initializes a requested number of execution environments so that they are prepared to respond immediately to your function's invocations. Note that configuring provisioned concurrency incurs charges to your AWS account.
Source: https://docs.aws.amazon.com/lambda/latest/dg/provisioned-concurrency.html
With provisioned concurrency whenever you know that extra concurrency for a given function will be needed (because it's going to be executed e.g. during a Black Friday promotion), you can prepare up-front a given number of warm execution environment for your function. When you configure a number for provisioned concurrency, Lambda initializes that number of execution environments. Your function is ready to serve a burst of incoming requests with very low latency. When all provisioned concurrency is in use, the function scales up normally to handle any additional requests.
5. Protect downstream resources with reserved concurrency
Reserved concurrency guarantees the maximum number of concurrent instances for a given Lambda function. When a function has reserved concurrency, no other function can use that concurrency. There is no charge for configuring reserved concurrency for a function.
You might be thinking - why would I want to limit the maximum number of concurrent executions of a given function? Won't it get throttled at some point?
Yes, and that might be the desired behavior in some cases. Imagine that a Lambda function is calling a downstream legacy API that can only handle 10 requests at the same time. By setting a reserved concurrency of 10, you're making sure that even if your function is called more than 10 times, the downstream service won't be overloaded. While some requests may get throttled, it's better for a client to use an exponential backoff retry strategy than to make the legacy API explode (and inevitably wake up the poor soul on on-call duty).
6. Set conservative timeouts
The maximum timeout value you can configure for an AWS Lambda function is 15 minutes. While it might be tempting to always set a timeout of 15 minutes (e.g. to avoid timeout alerts), in my opinion it's not a good idea to do so.
In fact, in order to keep an eye on performance/latency issues, Lambda function timeouts should be rather conservative - if a given function should execute under a second than the configured timeout should reflect that.
Otherwise you may risk unnecessary costs - if a bug were introduced to your most-invoked function, bumping its duration to e.g. 5 minutes you wouldn't even notice due to its high timeout value (but you'll definitely notice the difference on your AWS bill). In addition to that, your UX will suffer since the user will be waiting for a long time for a response from your function.
That's why proper monitoring/alerting and conservative timeouts greatly help with providing the best latency for your clients.
7. Consider taking advantage of multi-threaded programming
In one of previous sections we've established that a Lambda function can use up to 6 vCPU cores and up to 10 GB of memory. At 1,769 MB, a function has the equivalent of one vCPU (one vCPU-second of credits per second), and above this value we get access to 2vCPU cores and more (depending on the memory setting).
What this boils down to is after crossing the threshold of ~2GB of memory, you can start using multi-threaded programming in your Lambda function to optimize its performance. This is of course easier said than done (and heavily depends on the programming language of choice as well as developer's skills), but is certainly an option. Optimizing work to be done in parallel on multiple vCPU cores will bring latency and cost of a function down.
It's not clear at which point Lambda function receives access to more than 2 vCPU cores. A AWS re:Invent 2020 Day 3: Optimizing Lambda Cost with Multi-Threading suggests that after crossing 3GB of memory a function receives 3 vCPU cores, 4 cores at ~5308MB, 5 cores at ~7077MB and 6 cores at ~8846MB. I was unable to find an official confirmation of those values published anywhere in AWS Lambda documentation.
8. Save on AWS Lambda Amazon CloudWatch Logs costs
Our friend, Wojciech Matuszewski published an entire post on this topic, which you are welcome to read here: Saving on AWS Lambda Amazon CloudWatch Logs costs
References:
- "Serverless Architectures on AWS"
- https://www.sentiatechblog.com/aws-re-invent-2020-day-3-optimizing-lambda-cost-with-multi-threading
- https://docs.aws.amazon.com/lambda/latest/dg/provisioned-concurrency.html
- https://aws.amazon.com/blogs/compute/operating-lambda-performance-optimization-part-1/
- https://aws.amazon.com/blogs/compute/operating-lambda-performance-optimization-part-2/
- https://aws.amazon.com/blogs/compute/operating-lambda-performance-optimization-part-3/
- https://docs.aws.amazon.com/lambda/latest/dg/configuration-concurrency.html
- https://aws.amazon.com/premiumsupport/knowledge-center/lambda-concurrency-limit-increase/
- https://aws.amazon.com/lambda/
- https://aws.amazon.com/blogs/developer/modular-packages-in-aws-sdk-for-javascript/
- https://docs.aws.amazon.com/lambda/latest/dg/invocation-scaling.html#scaling-behavior
- https://dzone.com/articles/understanding-retry-pattern-with-exponential-back
Tired of switching between AWS console tabs? 😒
Cloudash provides clear access to CloudWatch logs and metrics, to help you make quicker decisions.
Try it for free: